- 数据流
- Elasticsearch
Data stream 的概念
时序性数据
时间序列数据( time series data )是在不同时间上收集到的数据,用于所描述现象随时间变化的情况。这类数据反映了某一事物、现象等,随时间的变化状态或程度。
总的来说,这类数据主要基于时间特性明显,随着时间的流逝,往往过去时间的数据没有现在时间的重要或者敏感。
对于 Elastisearch 处理时序性数据,有人总结了主要有以下特点:
- 由时间戳 + 数据组成。基于时间的事件,可以是服务器日志或者社交媒体流。
- 通常搜索最近事件,旧文件变得不太重要。
- 索引的使用主要基于时间,但是数据并不一定随着时间均衡分布。
- 时序性数据一旦存入后很少修改。
- 时序性数据随着时间的增加,数据量会很大。
Elastisearch 在时序性数据的使用中,往往会有以下的缺点:
- 索引随着时间增加而数目较多。
- 索引大小无法均衡。
- 管理索引成本较高,需要维护 merge 合并删除等一系列任务。
- 节点资源与冷热数据分布不匹配。
在这样的一个场景下,数据流 Data stream 应运而生。
Data stream (数据流)是 Elastic Stack 7.9 的一个新的功能。Data stream 可以跨多个索引存储只追加时序性数据,同时为查询写入等请求提供唯一的一个命名资源。Data stream 非常适合日志,事件,指标以及其他持续生成的数据。
简单来说,Data stream 根据模板生成存储数据的后备索引,然后自动将搜索或者索引请求路由到存储流数据的后备索引。而这些后备索引则根据索引生命周期管理( ILM )来自动管理。
Data stream 的组成
数据流在 Elasticsearch 集群中由一个或多个隐藏的、自动生成的后备索引组成。
在实际的 Elasticsearch 操作中,数据流依靠索引模板来设定数据流实体的后备索引。
- 模板包含用于配置流的后备索引的映射和设置。
- 同一个索引模板可用于多个数据流。
- 不能删除数据流正在使用的索引模板。
每个索引到数据流的文档,必须包含一个 @timestamp 字段,映射为 date 或 date_nanos 字段类型。如果索引模板没有为 @timestamp 字段指定映射,Elasticsearch 将 @timestamp 映射为带有默认选项的日期字段。
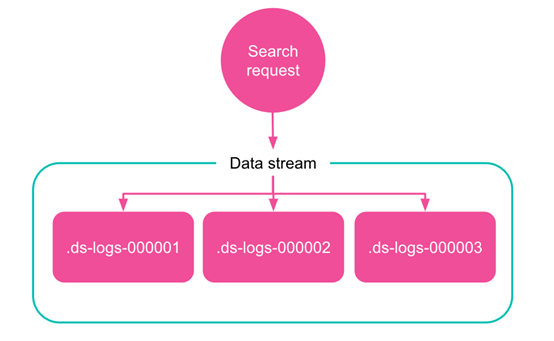
Data stream 的读请求主要如下图,数据流自动将请求路由到其所有后备索引。
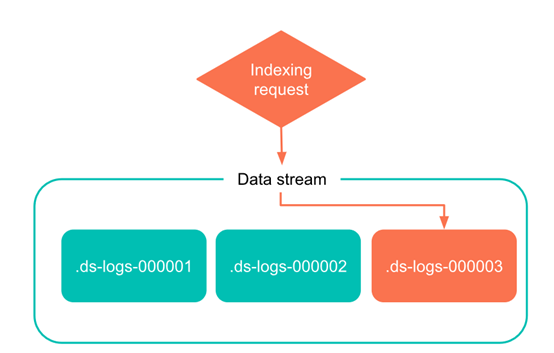
而对于写请求,数据流则将该请求自动转发给最新的后备索引。
Data stream 的特性
生成
每个 Data stream 的后备索引都有一个 generation 数,一个六位数,零填充的整数,从 000001 开始,用作该流的 rollover 的计数。
后备索引名主要依照以下格式:
.ds–
Generation 越大,后备索引包含的数据越新。 例如,web-server-logs 数据流最新的 generation 为 34。该流的最新后备索引名为 .ds-web-server-logs-000034。
注意:某些操作(例如 shrink 或 restore )可以更改后备索引的名称。 这些名称更改不会从其数据流中删除后备索引。
Rollover
在 Data stream 的使用中,rollover 是必不可少的条件。
创建数据流时,Elasticsearch 会自动为该 Data stream 根据 template 创建一个后备索引。 该索引还充当流的第一个写入索引。当满足一定条件时, rollover 会创建一个新的后备索引,该后备索引将成为 Data stream 的新写入索引。
当然 rollover 的条件设置主要依靠 ILM。 如果需要,你还可以手动将数据 rollover 。
追加
由于时序性数据的特征,Data stream 的设计场景中,数据是只追加的,极少需要修改删除。如果实际需要修改删除,则可以考虑以下操作:
- 对于数据流只能通过 update by query 或者 delete by query 操作,不能进行 update 或者 delete 文档。
- 需要 delete 或者 update 文档,则直接对后备索引操作。
- 需要经常删除或者修改文档的,请使用索引别名或者索引模板,不要对 Data stream 操作。
Data stream 的使用
创建索引生命周期管理策略 ILM
索引生命周期管理策略 ILM 的主要配置细节见索引周期管理一章,此处主要做 hot 和 delete 阶段的设置,用于 rollover 的引用。
|
|
创建索引模板
索引模板是后备索引设置,以及 mapping 的主要配置来源,此处不展开延伸。主要设置 Data stream 相关的部分。
相关命令:
|
|
注意:
- 定义 data_stream 为一个空的 object ,这是必要的。
- Template 中使用了上一步创建的 ILM 策略 my-data-stream-policy。
此外,还需要注意两点:
- Elasticsearch 有一些内置索引模板如 metric-- 和 logs-- ,默认优先级 priority 是 100。如果有重名使用,则可以调高优先级,防止被默认的覆盖。
- 索引模板默认将 @timestamp 字段设置为 date 属性
创建 Data stream
可以自动利用 template 的匹配模式新增文档创建
|
|
删除
删除命令:
|
|
删除数据流会将数据流的后备索引一起删除。
使用 Data stream
此处对数据流的操作主要以命令为主
新增数据
Data stream 在新增数据时是只追加的模式,因此在固定 id 和 bulk 的模式下,op_type 是指定 create 的。
如下面命令:
|
|
或者
|
|
或者
|
|
因字段中@timestamp是必填,实验数据如下改动:
|
|
获取 Data stream 状态
使用 Data stream stats API 查看 Data stream 的状态。
|
|
同时需要用 _ilm/explain 获取 Data stream 后备索引所在的 ILM 策略状态。
|
|
手动 rollover Data stream
使用 rollover API,手动 rollover Data stream。
|
|
Response:
|
|
再 GET 相关 Data stream 状态,后备索引增加。
|
|
Response:
|
|
Reindex Data stream
使用 reindex API 去复制数据到一个 Data stream。由于 Data stream 的只追加特性,在 op_type 中要选择为 create 。
|
|
Response:
|
|
Delete/Update by query
针对 Data stream 只能 delete/update by query 。
相关命令:
|
|