1.1 Kafka入门
一、Kafka 是什么?
有人说世界上有三个伟大的发明:火,轮子,以及 Kafka。
发展到现在,Apache Kafka 无疑是很成功的,Confluent 公司曾表示世界五百强中有三分之一的企业在使用 Kafka。在流式计算中,Kafka 一般用来缓存数据,例如 Flink 通过消费 Kafka 的数据进行计算。

关于Kafka,我们最开始需要了解的是以下四点:
1.Apache Kafka 是一个开源 消息 系统,由 Scala 写成。是由 Apache 软件基金会开发的 一个开源消息系统项目。
2.Kafka 最初是由 LinkedIn 公司开发,用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础,现在它已被多家不同类型的公司作为多种类型的数据管道和消息系统使用。
3.Kafka 是一个分布式消息队列。Kafka 对消息保存时根据 Topic 进行归类,发送消息 者称为 Producer,消息接受者称为 Consumer,此外 kafka 集群有多个 kafka 实例组成,每个 实例(server)称为 broker。
4.无论是 kafka 集群,还是 consumer 都依赖于 Zookeeper 集群保存一些 meta 信息, 来保证系统可用性。
二、为什么要有 Kafka?
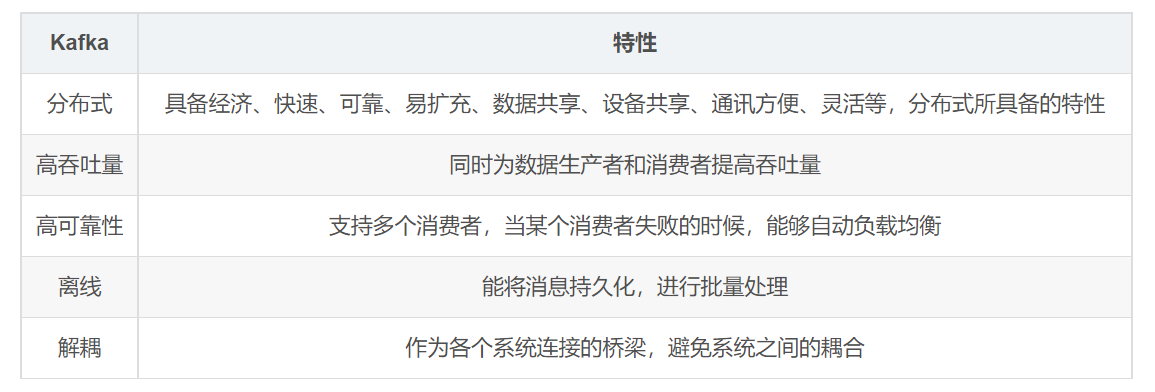
kafka 之所以受到越来越多的青睐,与它所扮演的三大角色是分不开的的:
消息系统:kafka与传统的消息中间件都具备系统解耦、冗余存储、流量削峰、缓冲、异步通信、扩展性、可恢复性等功能。与此同时,kafka还提供了大多数消息系统难以实现的消息顺序性保障及回溯性消费的功能。
存储系统:kafka把消息持久化到磁盘,相比于其他基于内存存储的系统而言,有效的降低了消息丢失的风险。这得益于其消息持久化和多副本机制。也可以将kafka作为长期的存储系统来使用,只需要把对应的数据保留策略设置为“永久”或启用主题日志压缩功能。
流式处理平台:kafka为流行的流式处理框架提供了可靠的数据来源,还提供了一个完整的流式处理框架,比如窗口、连接、变换和聚合等各类操作。
三、Kafka 基本概念
在深入理解 Kafka 之前,可以先了解下 Kafka 的基本概念。
一个典型的 Kafka 包含若干Producer、若干 Broker、若干 Consumer 以及一个 Zookeeper 集群。Zookeeper 是 Kafka 用来负责集群元数据管理、控制器选举等操作的。Producer 是负责将消息发送到 Broker 的,Broker 负责将消息持久化到磁盘,而 Consumer 是负责从Broker 订阅并消费消息。Kafka体系结构如下所示:
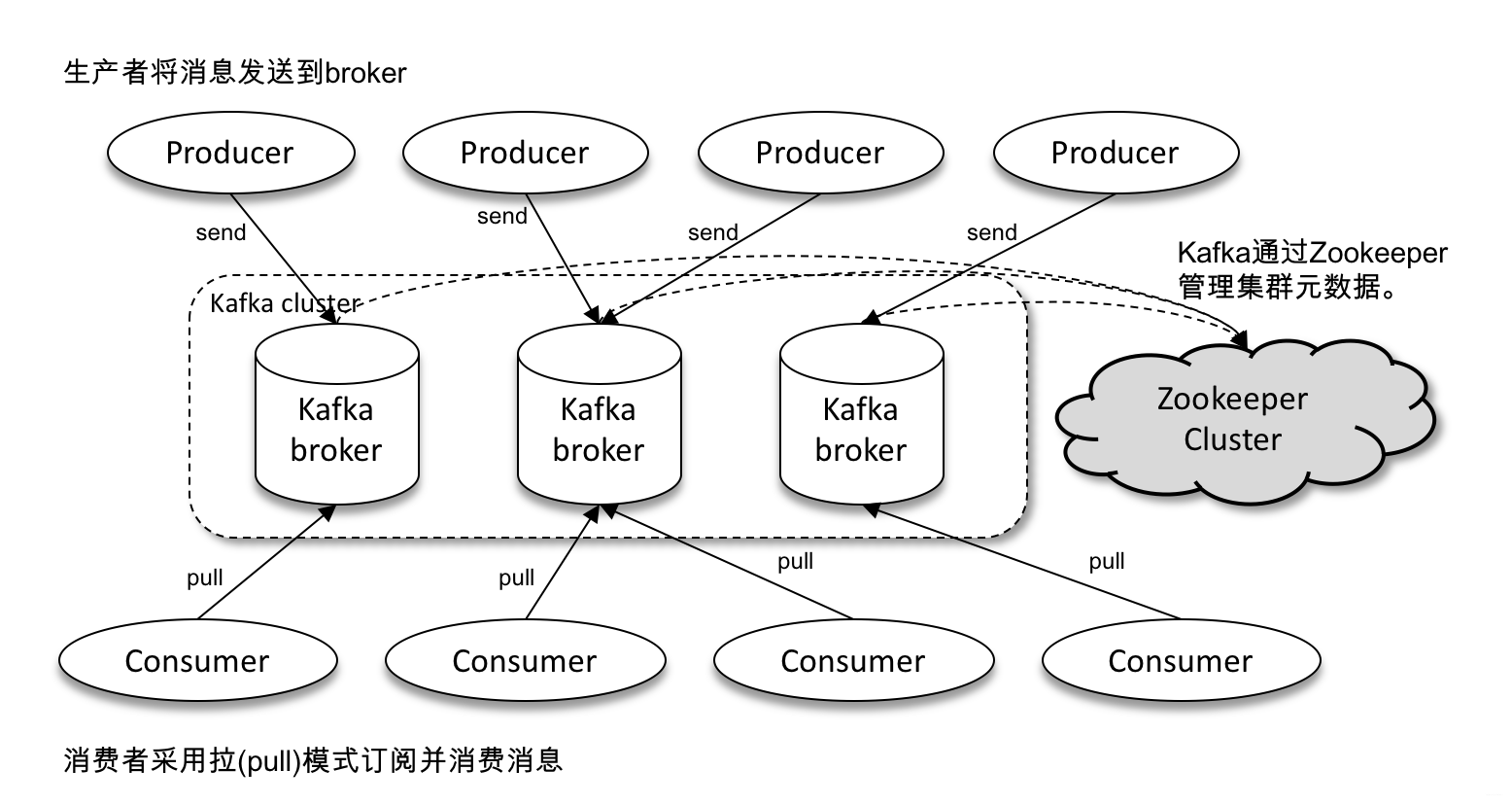
概念一:生产者(Producer)与消费者(Consumer)
对于 Kafka 来说客户端有两种基本类型:生产者(Producer)和 消费者(Consumer)。除此之外,还有用来做数据集成的 Kafka Connect API 和流式处理的 Kafka Streams 等高阶客户端,但这些高阶客户端底层仍然是生产者和消费者API,只不过是在上层做了封装。
Producer :消息生产者,就是向 Kafka broker 发消息的客户端;
Consumer :消息消费者,向 Kafka broker 取消息的客户端;
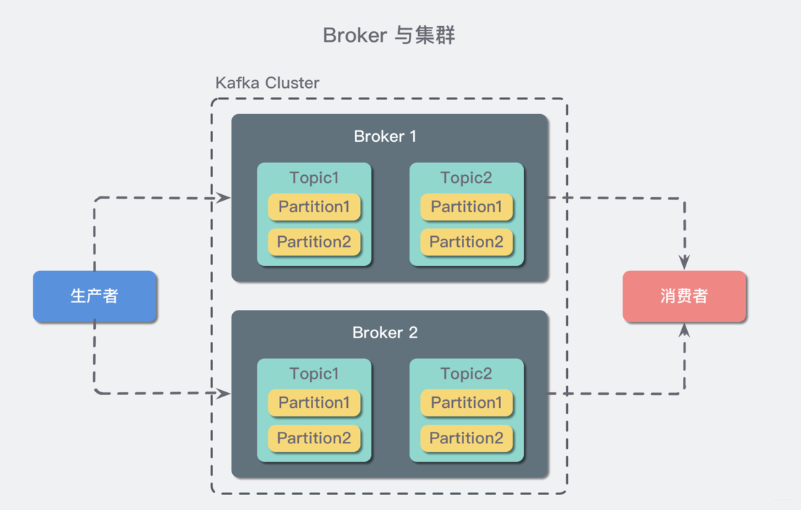
概念二:Broker 和集群(Cluster)
一个 Kafka 服务器也称为 Broker,它接受生产者发送的消息并存入磁盘;Broker 同时服务消费者拉取分区消息的请求,返回目前已经提交的消息。使用特定的机器硬件,一个 Broker 每秒可以处理成千上万的分区和百万量级的消息。
若干个 Broker 组成一个 集群(Cluster),其中集群内某个 Broker 会成为集群控制器(Cluster Controller),它负责管理集群,包括分配分区到 Broker、监控 Broker 故障等。在集群内,一个分区由一个 Broker 负责,这个 Broker 也称为这个分区的 Leader;当然一个分区可以被复制到多个 Broker 上来实现冗余,这样当存在 Broker 故障时可以将其分区重新分配到其他 Broker 来负责。下图是一个样例:
概念三:主题(Topic)与分区(Partition)
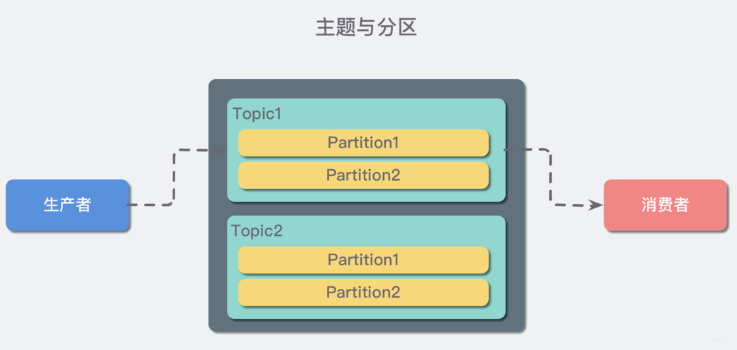
在 Kafka 中,消息以 主题(Topic)来分类,每一个主题都对应一个「消息队列」,这有点儿类似于数据库中的表。但是如果我们把所有同类的消息都塞入到一个“中心”队列中,势必缺少可伸缩性,无论是生产者/消费者数目的增加,还是消息数量的增加,都可能耗尽系统的性能或存储。
Kafka是天然分布式的。
备份分区仅仅用作于备份,不做读写。如果某个Broker挂了,那就会选举出其他Broker的partition来作为主分区,这就实现了高可用。
另外值得一提的是:当生产者把数据丢进topic时,我们知道是写在partition上的,那partition是怎么将其持久化的呢?(不持久化如果Broker中途挂了,那肯定会丢数据嘛)。
Kafka是将partition的数据写在磁盘的(消息日志),不过Kafka只允许追加写入(顺序访问),避免缓慢的随机 I/O 操作。
- Kafka也不是partition一有数据就立马将数据写到磁盘上,它会先缓存一部分,等到足够多数据量或等待一定的时间再批量写入(flush)。
消费者在读的时候也很有讲究:正常的读磁盘数据是需要将内核态数据拷贝到用户态的,而Kafka 通过调用sendfile()直接从内核空间(DMA的)到内核空间(Socket的),少做了一步拷贝的操作。

附docker-compose.yml 脚本
|
|
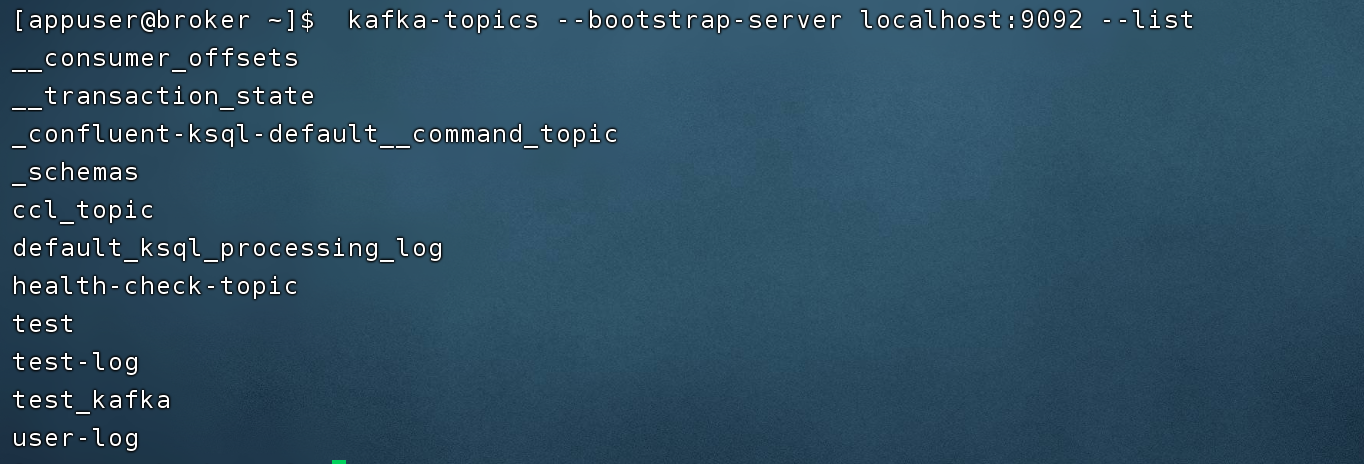
Kafka topic CLI:
|
|
|
|

|
|

|
|
|
|
|
|
|
|
|
|
|
|
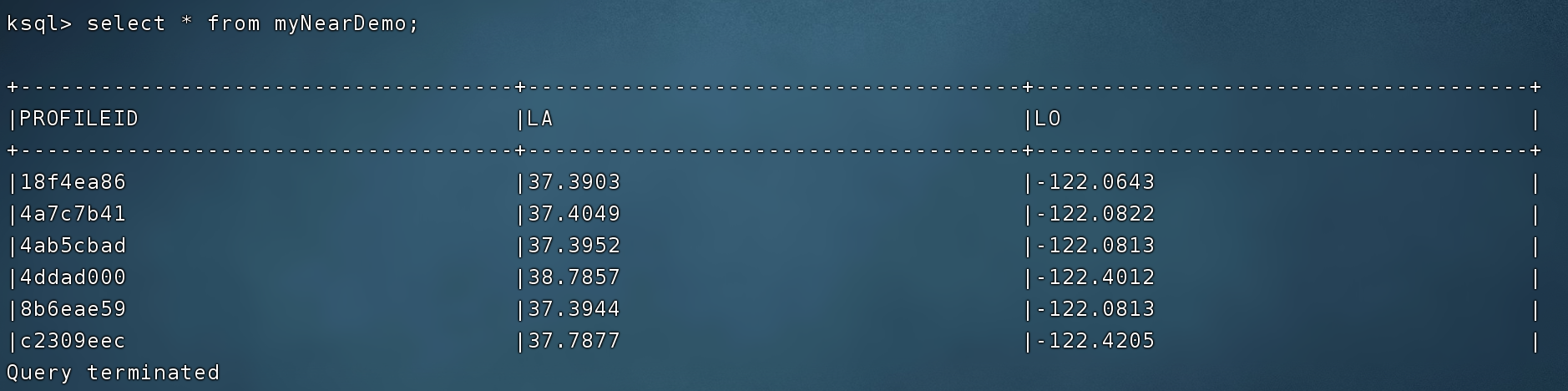
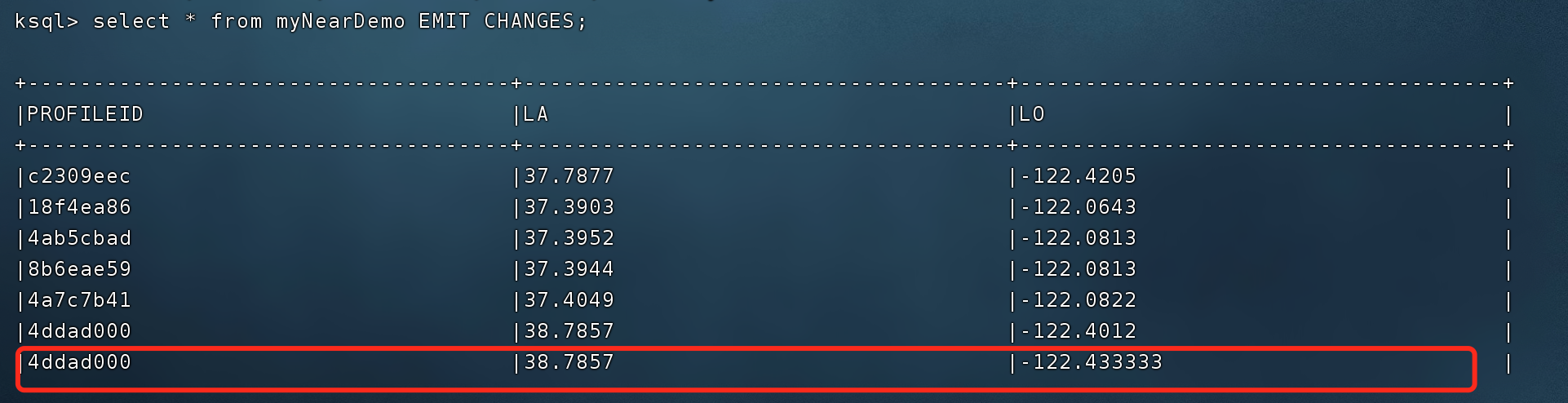
监测变化
|
|

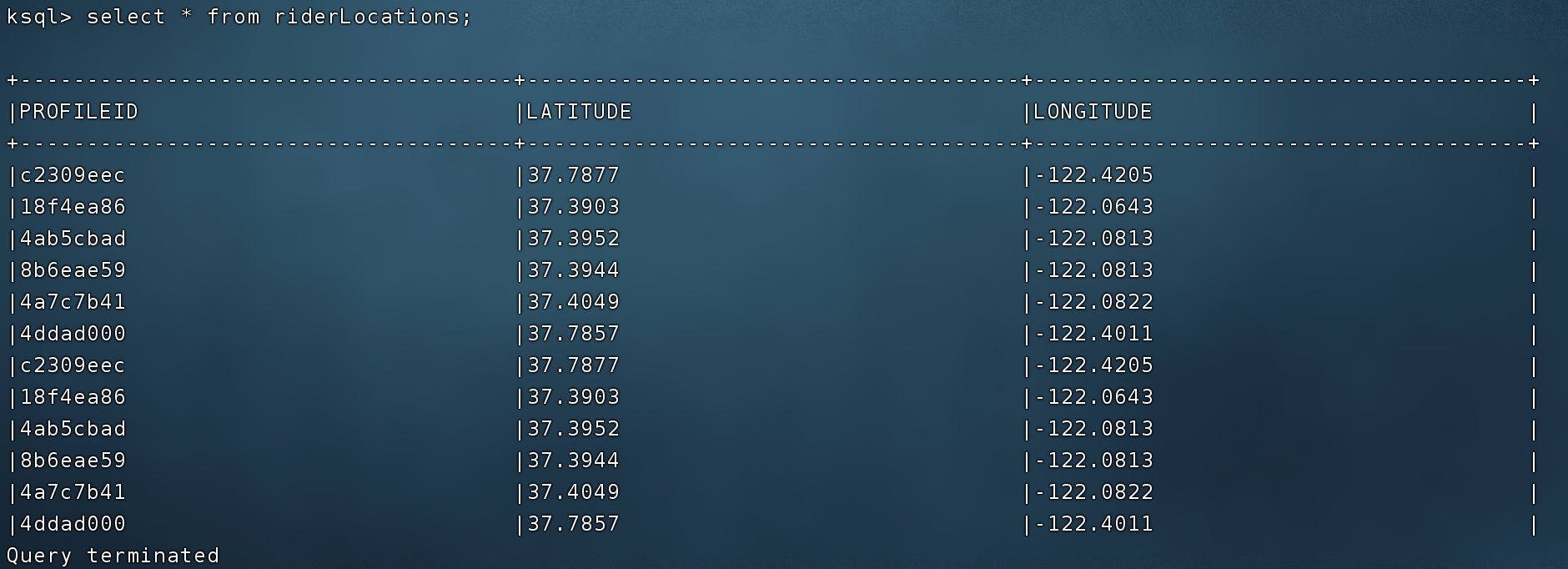
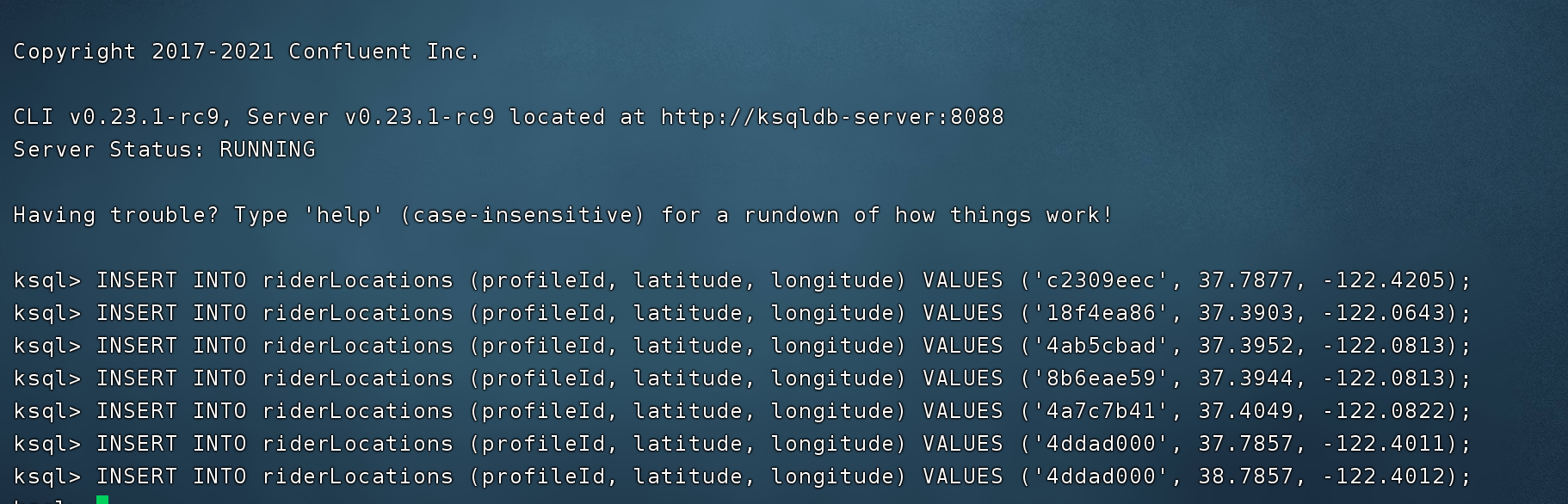
原始流 stream 里插入元数据
|
|